
Introduction to Elasticsearch.
The distributed and scalable search engine at the heart of the Elastic Stack.



Elasticsearch is an open-source, distributed full-text search engine based on the Apache Lucene library that can horizontally scale Lucene indices. Elasticsearch allows you to store, analyze and search a huge amount of data in near real-time. It is a document-oriented database that stores record as documents instead of rows and tables. And it also provides a rich set of Restful APIs to search and query the indexed data.
Elasticsearch Concepts
Documents Documents are the basic units of information that can be stored in elasticsearch and are similar to rows in relational databases. Documents are JSON objects with fields comprised of keys and values. A key is the name of the attribute (columns in a relational database) and the value can be of any datatype a string, a boolean, a number, an object or an array of values.
Indices Indices are logical namespaces containing documents that have similar characteristics.
MySQL -> Databases -> Tables -> Rows Elasticsearch -> Indices -> Types -> DocumentsIndices are similar to databases as in relational databases and an elasticsearch cluster can have multiple indices(similar to databases in a relational database) that can have multiple types ( similar to tables in a relational database) and types can have multiple documents (similar to rows in a relational database).
Inverted Index An Index is a mechanism for efficiency in databases. Elasticsearch splits the text or a sentence into individual words or terms and then maps each word or a term to the set of documents those search terms occur within. Elasticsearch makes use of distributed inverted indexes to quickly find matches for full-text search.
Components of Elasticsearch
Cluster A cluster is a group of one or more nodes connected together. The tasks are distributed across nodes to make use of parallel processing.
Nodes A server instance that is a part of the cluster.
- Master Node Responsible for cluster-wide operations like creating and deleting indexes, assigning shards and track of data nodes.
- Data Node Responsible to store data and performing data-related operations.
- Client Node Acts as a load balancer and forwards cluster requests to the master node and data-related requests to data nodes.
Shards Elasticsearch divides the index into multiple parts known as Shards that are distributed across multiple nodes. Elasticsearch itself manages these shards and rebalances the shards as necessary.
Replicas Replicas are copies of index's shards known as replica shards. By default, elasticsearch creates 1 primary shard and 1 replica shard for each index to protect against hardware failures.
Elastic Stack (ELK)
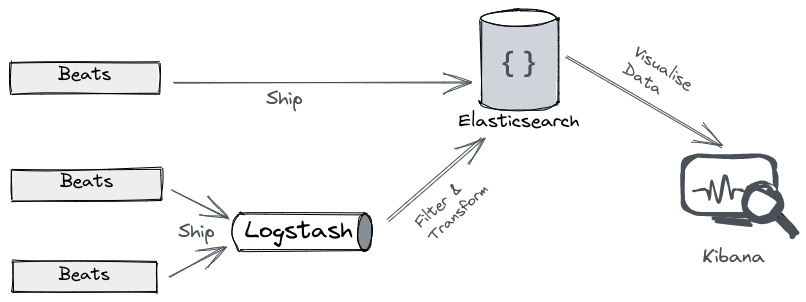
- Beats Lightweight data shippers that run on servers and capture the operational data and send it to elastic directly or via logstash.
- Logstash Server-side data processing pipeline that accepts data from multiple sources, transforms it and sends it to elastic.
- Kibana Browser-based analytics and search dashboard for elasticsearch.
Summary
Elasticsearch is a powerful search engine that can perform search queries in real-time even for larger datasets. Because of its distributed nature, it is a reliable, fault-tolerant and scalable solution to implement search functionality in applications. This article covers some of the fundamental terms and concepts of elasticsearch the upcoming articles would cover how CRUD operations are performed internally and indexing algorithm. Elasticsearch has a huge community you can easily find tutorials and articles to get started with elasticsearch.