What is Apache Lucene that powers Elasticsearch🚀
Lucene is an open-source Java library enabling powerful indexing and search operations. Elasticsearch is built on top of Lucene.


Lucene is the heart of elasticsearch, it is an open-source project maintained by Apache Foundation. We don't need to interact with it directly we have elasticsearch to work on our behalf 😌. Think of driving a car without asking the engine to start.
Before starting first understand what are shards and documents in elasticsearch 👉 introduction-to-elasticsearch
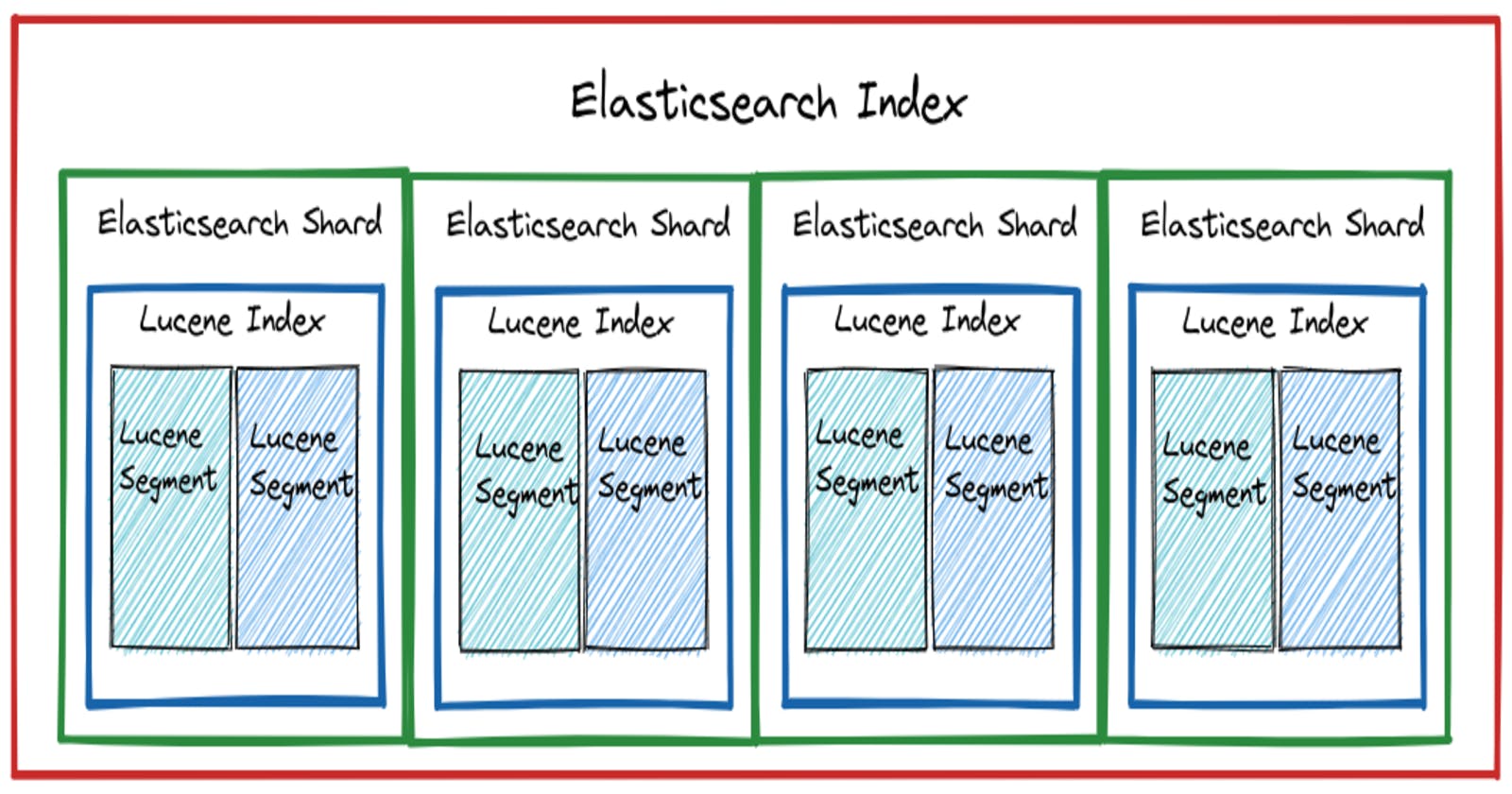
Lucene Index
An Index is used to search text in large datasets quickly, you first index the data and convert it into a format that is accessible by applications.
Lucene index is divided into multiple segments where each segment itself is composed of indexes that are not completely independent.
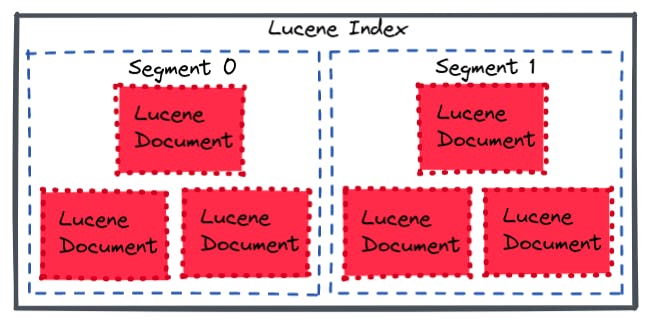
Lucene Segment
Each segment is a collection of one or more Lucene documents. Segments are immutable while deleting a document the document is marked as deleted and the new version of that document is added to the segment. Later at some point, these segments are merged into a single segment, not including the older versions that were marked as deleted. The main advantages of having a single merged segment are:
- Discard older version documents and reduce index space on disk.
- The old segments are removed and bigger segments are created which increases the search speed.
Conclusion
To understand the internal mechanism of CRUD operations in Elasticsearch knowing Lucene is the initial step. Elasticsearch is an abstraction layer over Lucene to provide distributed search engine that is horizontally scalable and provides JSON based APIs to interact with Lucene.